
在该系列文章的第一篇中,提到SEO应该是以数据为基础的,并略为展开写了一些数据方面的准备工作。数据虽然是非常重要的,但它扮演的角色只能是辅助:发现问题、总结改进、作为决策的参考因素等,但都无法脱离既有的SEO方法而独立存在。
而SEO的方法,应该分为两种或四种:使网站对搜索引擎友好、使网站对搜索引擎的用户友好。如果再考虑黑帽SEO手段的话,可以额外加上两项:使搜索引擎误以为网站对搜索引擎友好、使搜索引擎误以为网站对搜索引擎的用户友好。稍有经验的SEO,都可以总结下,看是否有任何SEO方法可以脱离这四点的范畴之外。至少我从没看到。
当然黑帽不在这系列文章的讨论范畴之内,所以就以两篇文章来分别简述如何对搜索引擎及其用户友好。
本文的主题是如何让网站对搜索引擎友好,这是一个非常大的话题,文章经过几次删改,最终还是决定只举一例。毕竟搜索引擎的技术涉及面实在太广,相应需要的网站技术也很多,一篇文章无论如何也最多提及冰山一角,那不如只找个比较有代表性的例子,剩下的大家自行扩展。
如何使搜索引擎能够更准确的理解网页?
搜索引擎无论如何只是程序,不可能非常完美判断互联网上那么多不同网页的不同情况。
搜索引擎对网页分析中的主要过程之一,是将网页分成一个个明确的功能区块。如正文区块、相关链接区块、联系电话区块、无关广告区块等等。而它判断的方式诸如:看字数多少、看HTML代码的形式、将文字内容以自然语言处理来理解等等。
分块化
一般在HTML代码里,最好以<div>标签来标明网页上的每一个重要区块,且每个重要的<div>里面又有一个<h2>或<h3>标签明确指明该区块的主题。这样的做法可以让页面上每一块内容所表达的更清晰。尤其对于搜索引擎而言,它可以通过这样的<div>来明确它如何去给网页分块,并通过小标题去了解这分块属于什么样的性质,从而判断应该如何计算处理。
一个最典型的实例是Amazon的产品信息页面:
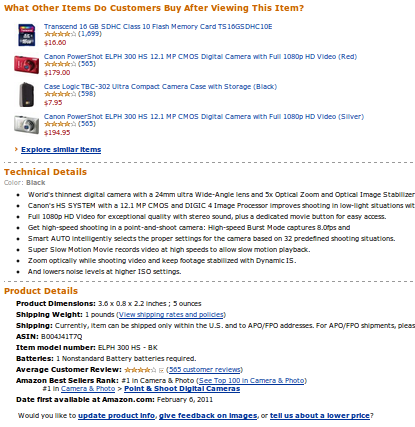
可以看到上图中被明确归为了三块,且清晰指出了它们分别是关联购买、技术细节与商品细节。相比之下,不少电商网站最上方是产品图片与价格,然后第二块区块开始,就把产品参数、产品描述及大量未必有用的产品图片依次堆在一起,无疑就差得多了。(上图中Product Details一块多数内容都是自动生成,而同时对用户和SEO有价值的内容,这块是被多数电商网站所忽略的。)
Amazon产品页的SEO,在电商领域是最顶尖的,远远强出eBay等网站。分块化便是其中主要原因之一。
语义化
这里语义化指的是用户所不可见的HTML代码也要具有含义,尽管这对于用户没有意义,但能让搜索引擎等程序更容易理解。(当然也方便代码维护,这是技术层面的事情了)
微数据、微格式等是已经日渐被重视起来的概念,它无疑可以很明确的标识网页上面元素的含义。这里不详细展开,可见:http://support.google.com/webmasters/bin/answer.py?hl=zh-Hans&answer=99170(微数据更重要的意义可能在于提升网页在SERP里面的点击率。对于电商网站,仅以此提升几倍SEO流量完全不是不可能的)。但微数据等方式总有一定的局限性,例如它不能指定大区块的含义,比如告诉搜索引擎,网页上哪里是头部、哪里是底部等。HTML5规范很好的解决了这个问题,它推荐使用的<header><footer>等标签可以非常好的展示网页区块。
不过很多网站目前基于很多原因还不会选用HTML5(但站在SEO的角度,应该尽力去推动下),所以不可以用<header>等标签,还是需要用<div>。在这样的情况下,需要注意<div>的ID命名。例如对于搜索引擎而言,<div id="header">要比<div id="toubu">容易理解得多。而且,一般来说可以用ID的地方不应该用CLASS,如不少设计人员喜欢不管三七二十一写<div class="header">。但W3C规范明确指出过,具有唯一性的元素应该使用ID而非CLASS。对于搜索引擎而言,具有唯一性的元素是可以确定其出现位置的,它就更容易确定那个区块到底在网页上起到什么样的角色。
举个实例如,以前公司里面有一个PPC的着陆页,明明网页上出现过相关的关键词,但那些词的质量分依然极低。分析后发现那些关键词都是被写在<div class="footer">区块的,这些文字就因此被当作页面底部的和主题无关的内容,使得搜索引擎错误的分析了网页,对质量分造成了负面的影响。
通俗化
通俗化在这里指的是不要在网页上用一些难以理解的指示性文字,比如在搜索框旁边使用“找找看”,而非常见的“搜索”。这会给用户带去一定程度的困扰,也会给搜索引擎带去更大的困扰。
搜索引擎会通过自然语言处理等方式来理解这样的文字。大致的思路如先随机抽取1000个网页样本,先人工找出网页上面的搜索区块,再通过机器分析这些区块一般出现什么样的字眼最多。那么相应的在分析日后其它网页的时候,出现这样字眼的区块也就更可能是搜索区块。
前面提到<div>命名的时候也差不多,<div id="header"><div id="head">等,因为都是比较常见的,搜索引擎肯定可以因此判断它为头部区块。而<div id="toubu">或更糟糕的(但不罕见的)<div id="h_1">等,搜索引擎就迷茫了。最终可能搜索引擎分析出来的结果不是自己想要的。
最后
前面以辅助搜索引擎理解网页为例,简单介绍了让网站对搜索引擎友好的思路。但搜索引擎不仅只是分析网页、就以分析网页而言,也远远不止上面这点内容。只能当作是思路的拓展。
如果可以的话,自己从服务器环境架设开始,从配置数据库、从框架构建程序、书写前端CSS与JavaScript等代码、尝试下Ajax、最好还自己搞定站内搜索,这样完完整整的做一个网站(在虚拟空间上用WordPress选一个模板就算搭建完的明显不算),就会发现不仅对于网页设计,在网站的各个角落都有SEO可以优化的空间。也只有自己实际做过,才能知道如何给具体技术人员写切实可行的文档。
关于前面提及的一些搜索引擎方面的知识,我在看过几本搜索引擎书后,相对而言入门级搜索引擎原理还是比较推荐《走进搜索引擎》一书。虽然从技术角度它没有什么独特的观念,但以较通俗易懂的方式很好的总结了基础的知识,对SEO而言还是很不错的。
另外,实际操作中总会碰上比理论中多得多的问题。比如前面的分块化的实现,对于一个小型B2C而言,或许SEO想到网页上面加一个产品参数区块时,会被告知:产品参数还没有录入过呢!
这样的尴尬事情总是存在,只能折中处理。比如在原先没有录入产品参数的情况下,可以先找网站某一个比较重要的商品分类去录入,并进行分块化的处理。过一段时间以数据来证明其SEO效果,以此推动其它部门进行更大规模的动作。
上面提到的数据,自然是要把该商品分类下的产品页额外筛选出来看的。有没有想起该系列文章前一篇提到的数据准备工作?此时就可以用上早已准备好的数据了。